Fundamentos de Networking en Kubernetes

Fundamentos de Networking en Kubernetes
Kubernetes es una plataforma de orquestación de contenedores que ha revolucionado la forma en que se desarrollan y despliegan aplicaciones en entornos de nube. Una parte fundamental de Kubernetes es su sistema de networking, que permite la comunicación entre los diferentes componentes del clúster y con el mundo exterior. Kubernetes ha ganado una gran popularidad en los últimos años debido a su capacidad para automatizar y escalar aplicaciones en entornos de contenedores. Una de las áreas clave en Kubernetes es el networking, que se encarga de facilitar la comunicación entre los diferentes servicios y contenedores desplegados en un clúster de Kubernetes.
En este artículo, exploraremos los fundamentos de networking en Kubernetes, incluyendo cómo se gestionan las comunicaciones entre los diferentes componentes de un clúster y cómo se implementan diferentes estrategias para optimizar el rendimiento y la seguridad de la red.
Modelo de Networking en Kubernetes
Kubernetes utiliza un modelo de networking basado en pods. Cada pod en un clúster de Kubernetes tiene una dirección IP única y puede comunicarse con otros pods, independientemente de en qué nodo se encuentren. Esto se logra mediante el uso de una red virtual superpuesta que conecta todos los pods en el clúster.
Existen diferentes modelos de networking que se pueden implementar en un clúster de Kubernetes, cada uno con sus propias ventajas y desventajas. Algunos de los modelos más comunes son:
- Overlay Networking: En este modelo, se crea una red virtual encapsulando el tráfico de red de los pods. Esto permite a los pods comunicarse entre sí a través de diferentes nodos en el clúster, sin importar su ubicación física. Ejemplos de soluciones de overlay networking son Flannel, Weave Net y Calico.
- L3 Networking: En lugar de encapsular el tráfico, en el modelo L3 el tráfico de red se enruta utilizando direcciones IP convencionales. Esto puede proporcionar un rendimiento mejorado en comparación con el overlay networking, pero puede ser más complejo de configurar y gestionar.
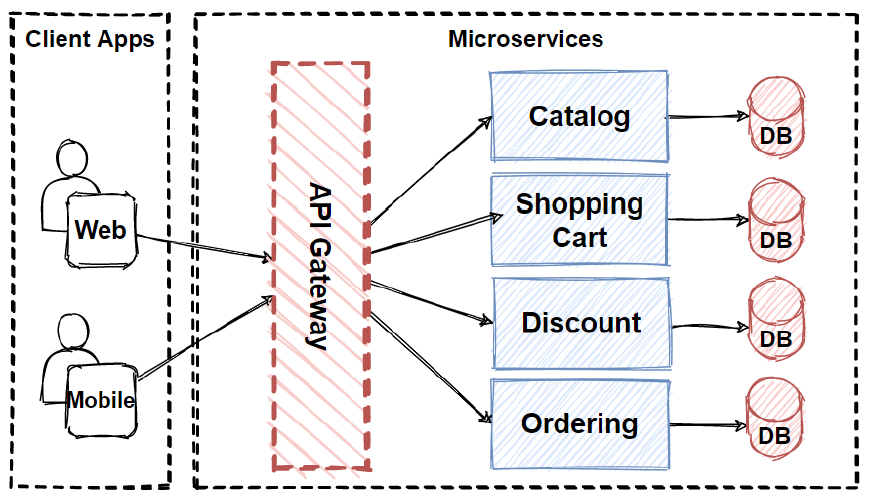
- Servicios de Kubernetes: Los servicios de Kubernetes facilitan la comunicación entre diferentes componentes de una aplicación, permitiendo descubrir de manera dinámica los pods que componen un servicio y enrutar el tráfico hacia ellos. Esto simplifica la configuración de redes de aplicaciones distribuidas.
Tipos de Tráfico de Red en Kubernetes
En Kubernetes, hay tres tipos principales de tráfico de red:
- Pod to Pod: La comunicación entre pods dentro del mismo clúster.
- Pod to Service: La comunicación entre pods y servicios dentro del clúster.
- External to Service: La comunicación entre el mundo exterior y los servicios expuestos en el clúster.
Componentes de Networking en Kubernetes
Para lograr la comunicación entre pods y servicios, Kubernetes utiliza varios componentes de networking:
- Kubelet: El agente de Kubernetes que se ejecuta en cada nodo y es responsable de la creación y gestión de pods.
- Kube-proxy: Un componente que se ejecuta en cada nodo y es responsable de enrutar el tráfico de red a los pods correctos.
- Plugins de Red: Kubernetes es compatible con varios plugins de red, como Flannel, Calico, Weave Net y más. Estos plugins proporcionan la red virtual superpuesta y gestionan el tráfico de red entre pods.
En un clúster de Kubernetes, existen diferentes componentes que intervienen en el networking. Algunos de los más importantes son:
- CNI (Container Networking Interface): Es una especificación que define cómo los contenedores se conectan a la red en un clúster de Kubernetes. CNI permite a los administradores de clústeres utilizar diferentes soluciones de networking según sus necesidades, como Calico, Flannel o Weave Net.
- Pods: Son la unidad básica de despliegue en Kubernetes. Un pod puede contener uno o más contenedores y comparten el mismo espacio de red, lo que facilita la comunicación entre ellos.
- Servicios: En Kubernetes, un servicio es una abstracción que define un conjunto de pods y una política por la cual acceder a ellos. Los servicios permiten descubrir de manera dinámica los pods que componen una aplicación y enrutar el tráfico hacia ellos.
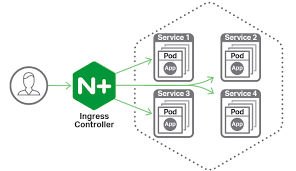
- Ingress: El Ingress es un recurso de Kubernetes que gestiona el tráfico de entrada a una aplicación, permitiendo configurar reglas de enrutamiento basadas en el host, la ruta, o cualquier otro parámetro. Esto facilita la exposición de servicios a través de una única dirección IP.
Servicios en Kubernetes
Los servicios en Kubernetes proporcionan una abstracción sobre un conjunto de pods y un punto de acceso estable para acceder a ellos. Hay varios tipos de servicios en Kubernetes:
- ClusterIP: Un servicio accesible solo dentro del clúster.
- NodePort: Un servicio accesible desde fuera del clúster a través de un puerto en cada nodo.
- LoadBalancer: Un servicio que utiliza un balanceador de carga externo para distribuir el tráfico a los pods.
- ExternalName: Un servicio que devuelve un nombre DNS externo en lugar de un IP.
Ingress en Kubernetes
Ingress es un recurso de Kubernetes que proporciona enrutamiento de tráfico HTTP y HTTPS a los servicios dentro del clúster. Ingress permite definir reglas de enrutamiento basadas en el host y la ruta, lo que facilita la exposición de múltiples servicios a través de un único punto de entrada.
Consejos para Optimizar el Networking en Kubernetes
A la hora de optimizar el networking en Kubernetes, es importante tener en cuenta algunos consejos clave:
- Segmentación de Red: Utilizar una segmentación de red adecuada para garantizar el aislamiento entre los diferentes servicios y aplicaciones desplegadas en el clúster.
- Monitoring y Logging: Implementar herramientas de monitorización y logging para detectar posibles cuellos de botella en la red y optimizar el rendimiento de la misma.
- Seguridad: Configurar políticas de seguridad en la red para proteger los servicios y aplicaciones desplegadas en el clúster de posibles amenazas externas.
- Balanceo de Carga: Utilizar un balanceador de carga para distribuir el tráfico de red de manera equitativa entre los diferentes pods y servicios desplegados en el clúster.
Conclusión
El networking es un componente crucial de Kubernetes que permite la comunicación entre los diferentes componentes del clúster y con el mundo exterior. Al comprender los conceptos básicos del networking en Kubernetes, como el modelo de networking basado en pods, los tipos de tráfico de red, los componentes de networking y los servicios, podrás diseñar y desplegar aplicaciones en Kubernetes de manera más efectiva.
El networking en Kubernetes es un aspecto fundamental a tener en cuenta a la hora de desplegar aplicaciones en entornos de contenedores. Comprender los fundamentos de networking en Kubernetes y aplicar las mejores prácticas puede ayudar a maximizar el rendimiento, la seguridad y la escalabilidad de las aplicaciones desplegadas en un clúster de Kubernetes.