IPS – Sistema de Prevención de Intrusiones

Sistema de Prevención de Intrusiones (IPS): Protegiendo tus Redes
Un sistema de detección de intrusiones (IDS, por sus siglas en inglés, Intrusion Detection System) es una herramienta de seguridad informática diseñada para monitorear y analizar el tráfico de red en busca de posibles actividades maliciosas o inusuales que puedan comprometer la seguridad de un sistema o red.
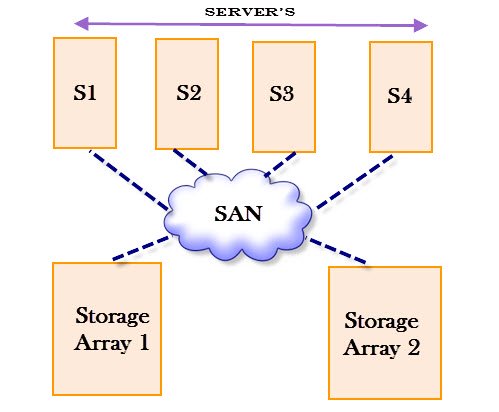
Existen dos tipos principales de IDS: los IDS de red y los IDS de host. Los IDS de red supervisan el tráfico de red en busca de patrones de ataques conocidos o comportamientos anómalos, mientras que los IDS de host se centran en la actividad en un sistema específico, como un servidor o una computadora individual.
Además, existe un sistema relacionado llamado Sistema de Prevención de Intrusiones (IPS, por sus siglas en inglés, Intrusion Prevention System), que va un paso más allá de la detección de intrusiones al tomar medidas activas para prevenir o detener ataques en tiempo real.
Los Sistemas de Prevención de Intrusiones (IPS) son una parte fundamental de la seguridad cibernética. Estos sistemas supervisan el tráfico de red en busca de posibles amenazas y actúan automáticamente para bloquearlas, alertando al equipo de seguridad y tomando medidas preventivas.
A continuación, exploraremos en detalle qué es un IPS, cómo funciona y por qué es crucial para la protección de tus redes.
¿Qué es un IPS?
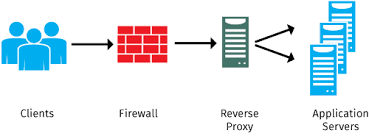
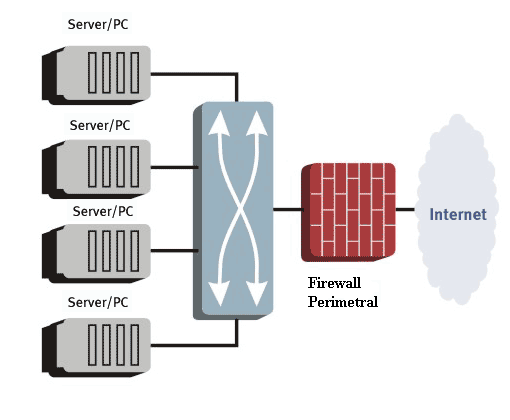
Un IPS es un dispositivo o software que se coloca en la ruta del tráfico de red para detectar y prevenir actividades maliciosas. Su objetivo es proteger la infraestructura de TI contra ataques y vulnerabilidades conocidas. Veamos sus características clave:
- Detección y Prevención: Un IPS no solo detecta amenazas, sino que también toma medidas para bloquearlas. Puede alertar al equipo de seguridad, terminar conexiones peligrosas, eliminar contenido maligno o activar otros dispositivos de seguridad.
- Evolución desde IDS: Los IPS evolucionaron a partir de los Sistemas de Detección de Intrusiones (IDS). Mientras que un IDS solo informa sobre amenazas, un IPS tiene capacidades automatizadas de prevención.
- Métodos de Detección:
- Basados en Firmas: Analizan paquetes de red en busca de firmas de ataque específicas. Si se encuentra una coincidencia, el IPS actúa.
- Basados en Anomalías: Utilizan inteligencia artificial y aprendizaje automático para crear un modelo de referencia de la actividad normal de la red. Cualquier desviación activa una respuesta.
Características principales de un IPS:
- Detección y prevención de amenazas: Un IPS monitoriza el tráfico de red en busca de patrones de ataques conocidos y comportamientos maliciosos, permitiendo identificar y detener las amenazas en tiempo real.
- Acciones proactivas: A diferencia de un IDS, que solo detecta intrusiones, un IPS utiliza reglas predefinidas o inteligencia artificial para detener las amenazas automáticamente, evitando que se materialicen en ataques exitosos.
- Bloqueo de tráfico sospechoso: Un IPS puede bloquear o filtrar el tráfico malicioso o inusual, ya sea rechazando paquetes, cerrando conexiones sospechosas o alertando a los administradores para que tomen medidas correctivas.
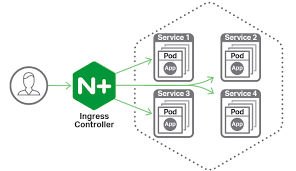
- Integración con sistemas de seguridad: Los IPS suelen integrarse con otros sistemas de seguridad, como firewalls y sistemas de detección de intrusiones, para proporcionar una defensa en capas más completa y eficaz.
Un IPS es una herramienta esencial en la seguridad cibernética moderna, ya que proporciona una capa adicional de protección proactiva al detectar, prevenir y detener posibles amenazas y ataques maliciosos en tiempo real. Su capacidad para actuar de manera automática y rápida frente a las amenazas lo convierte en una pieza clave en la defensa de redes y sistemas de información contra intrusiones.
Un IPS es esencial para proteger tus redes contra amenazas cibernéticas. Al combinar detección y prevención, estos sistemas ayudan a mantener la integridad y confidencialidad de tus datos.