Virtualización entre contenedores y máquinas virtuales
Diferencias entre la virtualización con contenedores y la virtualización con máquinas virtuales:
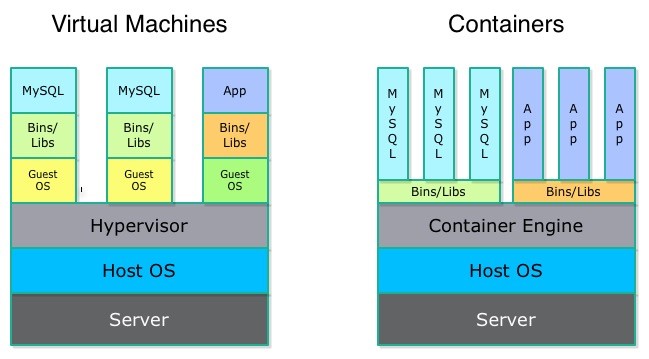
La principal diferencia entre la virtualización con contenedores y la virtualización con máquinas virtuales es que los contenedores virtualizan el sistema operativo para que la aplicación se pueda ejecutar de forma independiente en cualquier plataforma, mientras que las máquinas virtuales virtualizan toda una máquina hasta las capas de hardware. Además, los contenedores son más rápidos, portátiles y eficientes, mientras que las máquinas virtuales ofrecen una mayor seguridad y estabilidad. La elección entre contenedores y máquinas virtuales dependerá de las necesidades específicas de cada aplicación, proyecto o proceso.
¿Cuáles son las principales diferencias entre la virtualización con contenedores y la virtualización con máquinas virtuales?
Virtualización con contenedores:
- Virtualizan el sistema operativo para que la aplicación se pueda ejecutar de forma independiente en cualquier plataforma.
- Solo virtualizan las capas de software por encima del nivel del sistema operativo.
- Son más rápidos de implementar, permiten desplegar aplicaciones más rápido, arrancarlas y pararlas más rápido y aprovechar mejor los recursos de hardware.
- Son más portátiles y eficientes, lo que permite una mayor flexibilidad y eficiencia en la gestión de aplicaciones y servicios.
Virtualización con máquinas virtuales:
- Virtualizan toda una máquina hasta las capas de hardware.
- Pueden ejecutar cualquier sistema operativo y cualquier aplicación que se pueda ejecutar en una máquina física.
- Son más seguras y estables, ya que están completamente aisladas del sistema operativo subyacente.
- Pueden ejecutar muchas más operaciones que un contenedor individual.
Las ventajas de utilizar contenedores en lugar de máquinas virtuales son:
Ventajas de los contenedores:
- Son más rápidos de implementar al ser ligeros y solo incluir el programa y sus dependencias.
- Permiten desplegar aplicaciones más rápido, arrancarlas y pararlas más rápido y aprovechar mejor los recursos de hardware.
- Son más portátiles, lo que permite que las aplicaciones sean independientes de los recursos de la infraestructura de TI.
- Ofrecen una mayor eficiencia en la gestión de recursos, ya que utilizan una arquitectura de contenedores liviana y eficiente.
- Permiten estandarizar los entornos de desarrollo, prueba y producción, lo que reduce los problemas de compatibilidad y ayuda a evitar problemas de configuración.
- Permiten automatizar muchas tareas de configuración y despliegue de aplicaciones y servicios, lo que ahorra tiempo y recursos en la gestión de la infraestructura.
Ventajas de las máquinas virtuales:
- Pueden ejecutar muchas más operaciones que un contenedor individual.
- Permiten empaquetar las cargas de trabajo monolíticas.
- Son inmunes a cualquier vulnerabilidad o interferencia de otras máquinas virtuales en un host compartido.
- Permiten ejecutar varios sistemas operativos propios e individuales que se ejecuten en el mismo sistema operativo host.
- Ofrecen una mayor seguridad y estabilidad en la gestión de aplicaciones y servicios.
Los contenedores son más rápidos, portátiles y eficientes, mientras que las máquinas virtuales ofrecen una mayor seguridad y estabilidad.
Las desventajas de utilizar contenedores en lugar de máquinas virtuales son:
- Menor aislamiento: los contenedores comparten el mismo kernel del sistema operativo host, lo que significa que si hay una vulnerabilidad en el kernel, todos los contenedores pueden verse afectados. En cambio, las máquinas virtuales tienen su propio kernel y están completamente aisladas del sistema operativo host, lo que las hace más seguras.
- Limitaciones en la ejecución de aplicaciones: los contenedores están diseñados para ejecutar aplicaciones específicas y no son adecuados para ejecutar aplicaciones que requieren un sistema operativo completo o una configuración de hardware específica. En cambio, las máquinas virtuales pueden ejecutar cualquier sistema operativo y cualquier aplicación que se pueda ejecutar en una máquina física.
- Dependencia de la infraestructura del host: los contenedores dependen de la infraestructura del host para su ejecución, lo que significa que si el host falla, todos los contenedores también fallarán. En cambio, las máquinas virtuales son independientes del host y pueden ser migradas a otro host en caso de falla.
- Menor flexibilidad: los contenedores son más rígidos en cuanto a la configuración y no permiten la personalización de la configuración de hardware o software. En cambio, las máquinas virtuales permiten la personalización completa de la configuración de hardware y software.
Los contenedores tienen algunas desventajas en comparación con las máquinas virtuales, como un menor aislamiento, limitaciones en la ejecución de aplicaciones, dependencia de la infraestructura del host y menor flexibilidad en la configuración. Sin embargo, estas desventajas pueden ser mitigadas con una buena planificación y gestión de la infraestructura.